
Retrospect of ASPLOS 2024
During April 27-May 1, 2024, me and Heehoon attended ASPLOS 2024 in San Diego, USA. ASPLOS is the premier academic forum for computer systems research spanning hardware, software, and their interaction. This year, 170 accepted papers were presented orally in four sessions, and over 800 attendees gathered on site in-person. We were fortunate to present our paper, TCCL: Discovering Better Communication Paths for PCIe GPU Clusters.
Tutorial (Apr 27)
I attended PyTorch 2 workshop. PyTorch team core members attended the workshop to introduce two key components of PyTorch 2, TorchDynamo and TorchInductor. TorchDynamo converts a Python bytecode (PyTorch program) by extracting code segments into graphs (i.e., FX graphs), which is then compiled for optimized execution. TorchInductor enables Python-level accelerator code writing, which is then transformed into CUDA code (similar to Triton).

Workshop (Apr 28)
I attended 6th Young Architect Workshop (Yarch’24). Prof. Caroline Trippel, Prof. Dimitrios Skarlatos, and Dr. Martin Maas organized two keynotes and a panel discussion session “Demystifying Grad School”. During the discussion, Prof. Tim Sherwood emphasized to always keep curiosity inside our minds, which made me to retrospect my attitude towards broader systems research. As I focused on machine learning systems during my Masters’, I sometimes thought that traditional research areas would not have many research topics left; however, his quote remarked me that it is definitely not true. The panel and the student attendees had a round table lunch after the event. I also want to thank Prof. Hadi Esmaeilzadeh, Prof. Vijay Janapa Reddi, and Prof. Dimitrios Skarlatos for sharing their precious insights and enlightening experience stories during the lunch. I didn’t expect much before attending Yarch, yet it became one of the most wonderful experience of ASPLOS.

In the afternoon, I attended the debate, under the topic of “Should everyone work on machine learning/AI?”. It was sometimes very fun, and sometimes very insightful to listen to how the panels have so much different view on the topic.

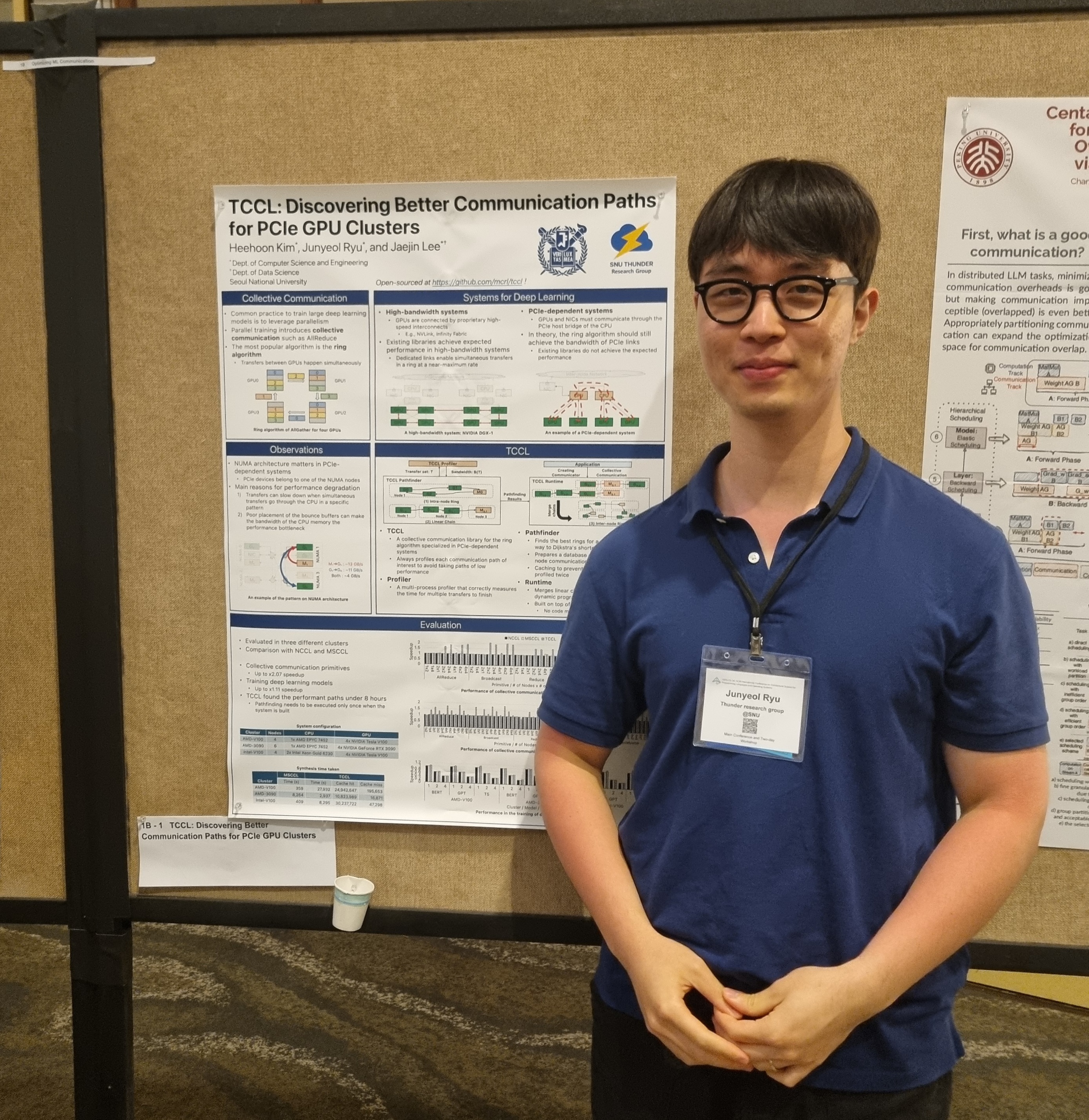
We presented the poster for our paper, TCCL, at the hall in evening. It was really fun as many people showed interest in our work and asked questions that some even aroused new research interests and curiosities in our minds. I especially want to thank Prof. John Kim and Mert Hidayetoglu, for sharing his similar experience encountering congestion on CPU while executing theoretically physically unoverlapped communication, and suggesting a heuristic-based approach to improve the consumed time for TCCL’s pathfinder, respectively.
Main program (Apr 29-May 1)
Heehoon presented TCCL in Session 1B: Optimizing ML Communication. Although it was the first session in the first day of the program, many people attended our presentation and asked questions during and after it. Other three papers of the session were about overlapping communication with computation, which also seemed to be interesting and important topic.

I found several papers very interesting.
- GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
Presented virtual memory stitching to ideally elimiate fragmentation in PyTorch CUDA caching allocator. The key technique is to reserve virtual address space with
cuMemAddressReserveand map physical memory chunks to reserved address withcuMemMap. - SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification Presented parallel speculative inference using Tree attention. The key technique is to generate speculated token tree from multiple SMTs, and aggregate the token trees to verify the ~ by LLM.
- Manticore: Hardware-Accelerated RTL Simulation with Static Bulk-Synchronous Parallelism TBD.
Others


Leave a comment