
TCCL: Discovering Better Communication Paths for PCIe GPU Clusters

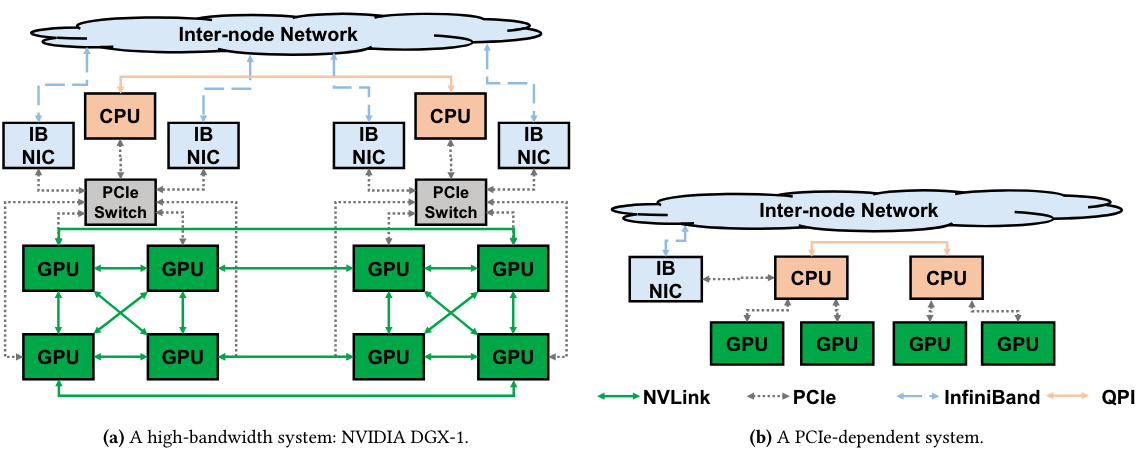
TCCL was recently published in ASPLOS 2024. This project initiated from a finding when Heehoon and I were experimenting collective communication performance of Mellanox SHARP.1 Our intention was to minimize the overhead of collective communications on PCIe-dependent systems, where the link bandwidth is too scarce (e.g., bidirectional 32GB/s for PCIe Gen3) compared to modern GPUs’ computation efficiency. However, experiment results showed that when NCCL uses ring algorithm (simultaneous transfers of a collective communication forms a ring), some rings suffer a significant performance degradation while others do not. We first suspected the shared NIC or IB switch, but the same problem was observed when only the GPUs in the same node is involved. It was unexpected, as the bidirectional PCIe links are not shared among simultaneous transfer of a ring algorithm. Hence, we started to think that there is some problem in the PCIe-dependent systems, and NCCL fails to mitigate it.
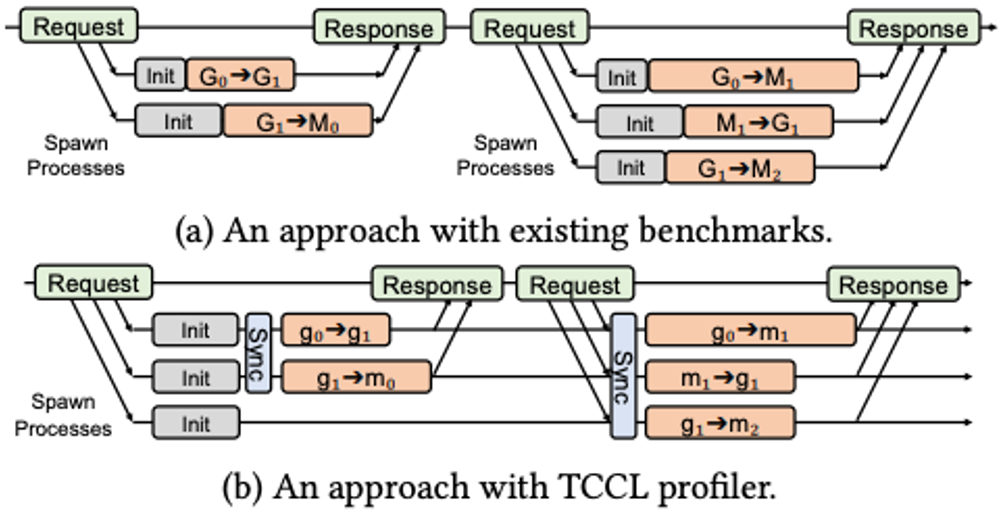
To pinpoint the root cause, we first tried to identify the transfer sets that incur congestion. However, existing benchmarks (e.g., OSU Micro-benchmarks, nvbandwidth, and Scope) that measure the latency and bandwidth of transfers involving GPUs and NICs were not suitable, since they had an initialization phase with a non-deterministic latency (e.g., due to memory allocation) that does not guarantee the transfers to start simultaneously. To this end, we implemented a profiler for accurate measurement of simultaneous multiple transfers and were able to identify several congestion patterns in different clusters.
After delving into the profiled sets, we found that one of the reasons is NUMA architectures. As PCIe-dependent systems must communicate through the PCIe host bridge of the CPU and possibly the interconnect between NUMA nodes or CPU sockets, transfers can slow down when multiple transfers go through the CPU in a specific pattern. Another is the poor placement of the bounce buffers when GPUs communicate via CPU memory due to lack of direct memory access support. Such congestion patterns are not identified nor avoided by the existing collective communication libraries because the phenomenon does not appear when communication utilizes links outside the CPU, as in high-bandwidth systems. There can be other causes, which we belive is an interesting open research problem.2
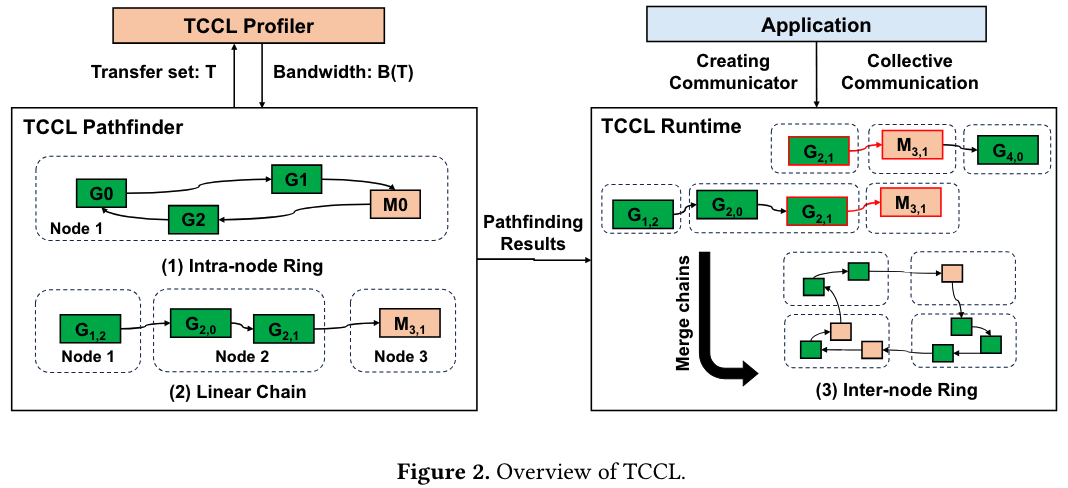
We needed an algorithm to find the best communication path among the GPUs in a cluster. It is infeasible to brute-force search all the communication paths, as the number of possible communication paths increases exponentially with the number of GPUs in a cluster. Also, it is difficult to build a concrete congestion model, as the architecture of the CPU is not known. For intra-node pathfinding, we developed an algorithm similar to Dijkstra’s shortest path algorithm and exploited a cache and NUMA symmetry. For inter-node pathfinding, we used dynamic programming to find the linear chain with the best bandwidth from merging. The final communication path avoids congestion by mainly two ways: (1) exploiting a bounce buffer on the CPU memory when transferring data between GPUs and NICs (e.g., while direct communication alone may have smaller latency and higher bandwidth, it may trigger congestion when used in collective communication where multiple transfers are in progress simultaneously), and (2) changing the virtual topology on which the collective communication algorithm operates (e.g., the order of GPUs in a ring).
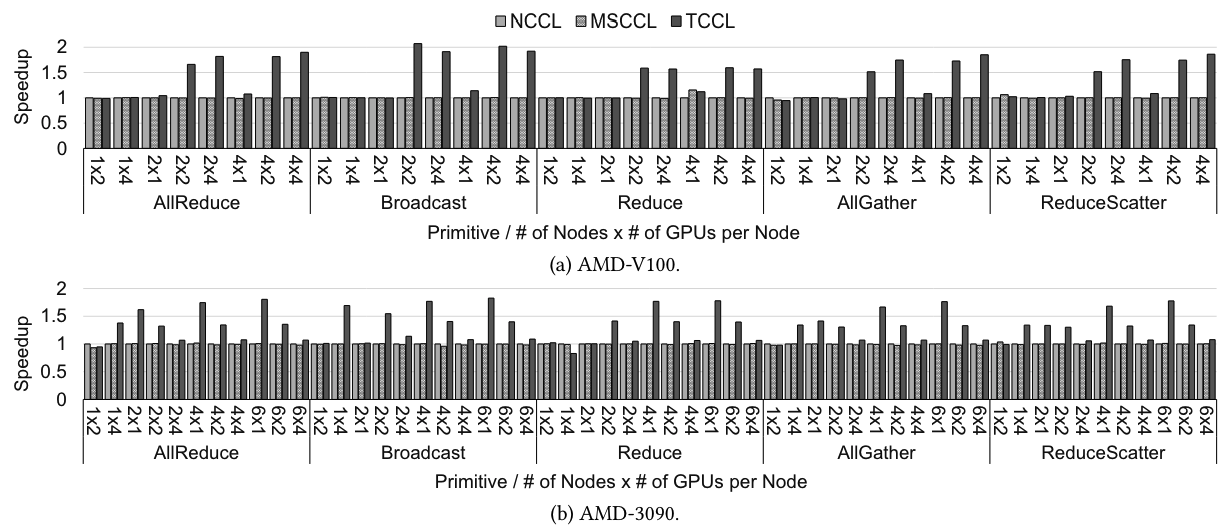
So, how good is TCCL? The evaluation results show that it is up to twice faster than the state-of-the-art collective communication libraries on PCIe-dependent systems. Also, it is implemented on top of NCCL, so users can transparently use TCCL without any code modification. If you are interested, find more in the paper.
-
An in-network aggregation technology that performs reduction using special circuit at Infiniband (IB) switch. Although parallelisms for machine learning (e.g., data parallelism and fully-sharded data parallelism) overlap computation and communication, the collective communications that involve reduction (e.g., AllReduce and ReduceScatter) require processing elements (PEs) to process reduction kernels, which contends with computation kernels. Using SHARP, it is possible to offload the computation for reduction to the IB switch, thereby maximize overlap of computation on the compute units (e.g., CPU and GPU) with collective communication and reduction on the IB switch. ↩
-
We were actually fortunate to talk with Prof. John Kim at the conference and he shared that similar problems were observed in his ISCA 2017 paper. ↩
Leave a comment