
TCCL: Discovering Better Communication Paths for PCIe GPU Clusters
TCCL (paper, code) is a project aimed at accelerating GPU communication on PCIe-dependent systems. Specifically, it targets collectives, such as All-Reduce and Reduce-Scatter, which involve simultaneous data transfers across GPUs and typically use the ring algorithm. Previous works take a heuristic approach based on the theoretical maximum bandwidth of links to form a ring. However, they fail to accurately model the path bandwidth, resulting in a suboptimal ring. To address this, TCCL proposes a pathfinding algorithm based on a profiling approach.
Problems
We discuss two of the cases where the heuristic approach fails to achieve accurate bandwidth modeling:
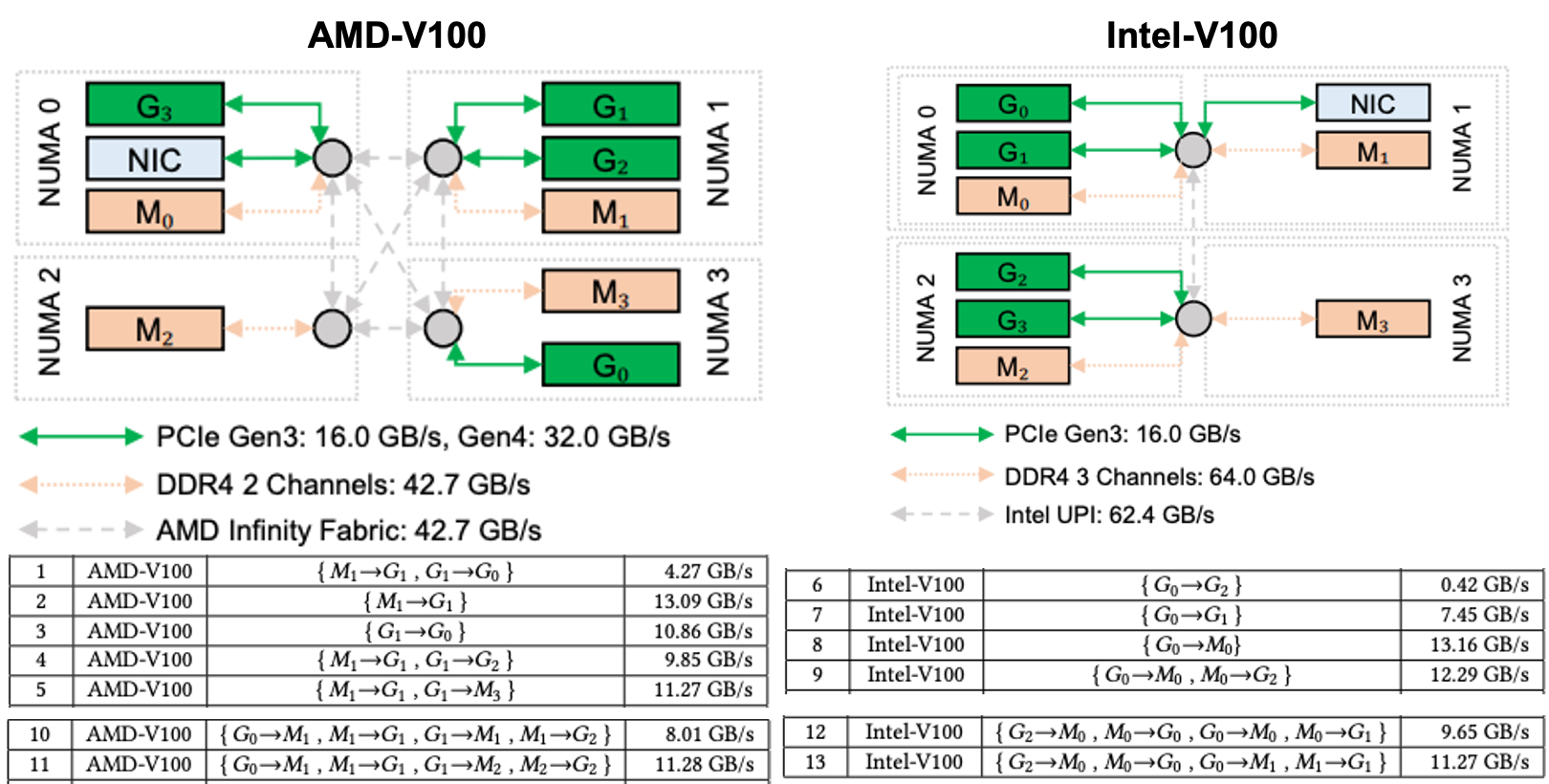
Congestion at CPU. In a Non-uniform Memory Access (NUMA) architecture, a specific set of memory channels, CPU cores, and PCIe lanes form a NUMA node. The PCIe devices attached to these lanes, such as GPUs and NICs, belong to the same NUMA node as the lanes. Accessing a remote NUMA node requires passing through the CPU-to-CPU interconnect. There are specific cases of bandwidth degradation when the path involves passing through the interconnect.
Poor placement of the bounce buffers. When GPUs do not use direct memory access (DMA), the sender writes to and the reader reads from a buffer in the CPU’s main memory. Even if the GPUs support DMA, there are specific cases where DMA is slower than using CPU memory bounce buffer. The buffer’s placement to which NUMA node is also important, because if all transfers use the buffer on the same NUMA node, the bandwidth degrades.
Below figure shows the examples of such cases. On AMD-V100, the most interesting congestion pattern is when a GPU reads from same NUMA node’s CPU memory while simultaneously writes directly to the memory of a GPU in a different NUMA node (No. 1-5). On Intel-V100, a direct transfer between the GPUs in different NUMA nodes suffer horrible performance while communication through a bounce buffer in the CPU memory does not (No. 6-9). Both systems experience performance degradation when too many transfers are concentrated on the CPU memory in the same NUMA node (No. 10-11 and No. 12-13).
Methods
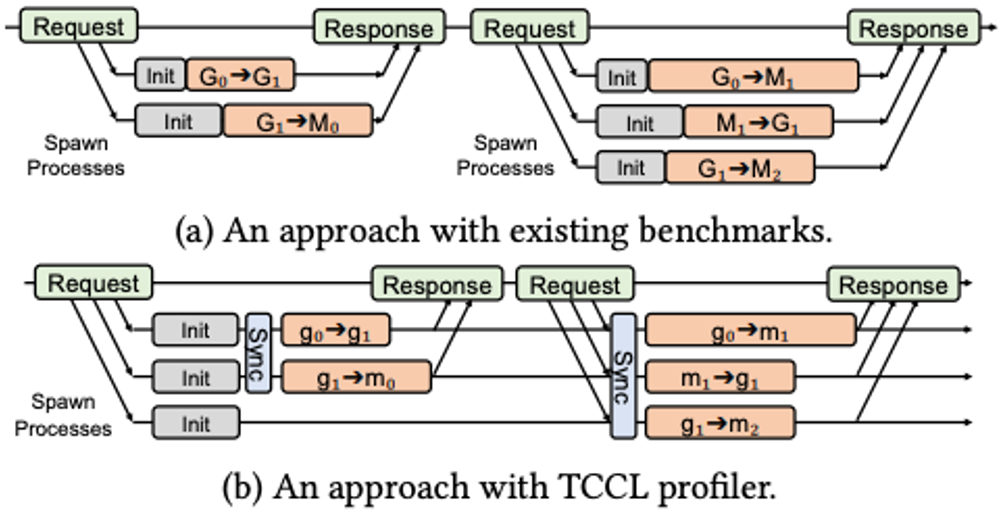
These congestion patterns are hard to detect with heuristic approach as they should not occur in theory. However, one limitation of existing profilers is that multiple transfers are not guaranteed to start simultaneously, leading to inconsistent overlap between transfers and resulting in inaccurate measurements. To this end, TCCL implements a multi-process profiler with a process pool to saturate initialization overhead, and guarantees consistent overlap between transfers using synchronization mechanism.
Since the number of possible paths increases exponentially with the number of GPUs, trying all paths is infeasible. TCCL uses an algorithm similar to Dijkstra’s shortest path algorithm and dynamic programming for intra-node and inter-node pathfinding, respectively. We discuss both in detail:
Intra-node pathfinding. The algorithm starts with a set of GPUs \(G\) to visit and a maximum priority queue \(Q\) that uses the bandwidth as a key and the transfer set as a value. In every iteration, it picks the current best transfer set \(T\) from \(Q\), appends all available transfers that advance \(T\) one step further to forming a ring. For example, if \(G\) is \({G_0,G_1,G_2}\) and \(T\) is \(G_0\)→\(G_1\)→\(G_2\), \(G_2\)→\(G_0\) can be added to make \(T\) a ring. Alternatively, \(G_2\)→\(M_i\) can be added to use a bounce buffer in a NUMA node \(i\) and let the future iteration add \(M_i\)→\(G_0\) to finish a ring. The new transfer sets are profiled by the TCCL profiler, and the result is inserted back into the priority queue. If a transfer set forms a ring, it is guaranteed with the best bandwidth among the rings of \(G\).
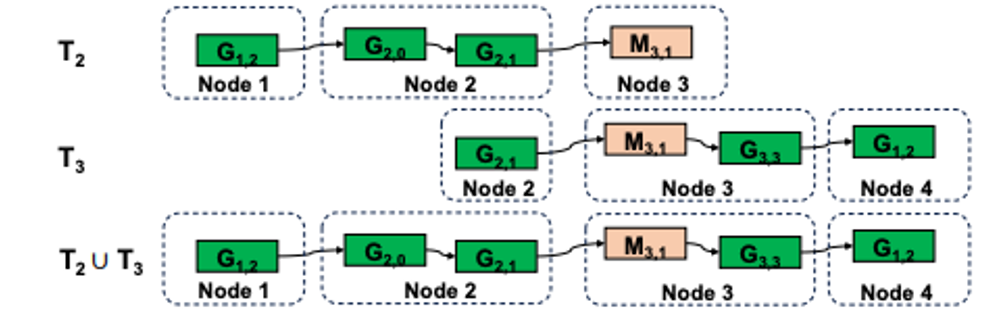
Inter-node pathfinding. Above algorithm is not directly applicable to the inter-node pathfinding because the number of different paths that travel through all GPUs in a cluster becomes extremely too large. Instead, TCCL first constructs intra-node linear chain (not a ring), which is a path that visits GPUs in a single node, using slight modification of intra-node algorithm. The best intra-node chains of node \(i\) is in the form of \(DB_{\text{inter},G_i}[h][t]\), where its head is \(h\) and tail is \(t\). Then, the linear chains of each node should be merged into a linear chain that visits all GPUs in a cluster, and joins both ends of the linear chain to form a ring. The dynamic programming’s subproblem is \(D[n][h][t]\), which is the best bandwidth of a linear chain that visits GPUs participating in collective communication from the first node to the \(n\)-th node. \(h\) is the head of the linear chain, and \(t\) is the tail of the linear chain. The best bandwidth of the merged linear chain can be solved iteratively with: \(𝐷[n][h][t] = max_x(D[n-1][h][x],DB_{\text{inter},G_n}[x][t])\), where \(x\) is an inter-node transfer. The algorithm merges the best \((n − 1)\)-node linear chain that ends with \(x\) and the best single-node linear chain that starts with \(x\) and saves the best after trying all available inter-node transfers. As a final step, the best ring can be found among linear chains where its head and tail can be joined to form a ring as: \(R = max_x(D[N][x][x])\) where \(N\) is the number of nodes, and \(R\) is the bandwidth for the final ring.
Performance
TCCL finds performant paths that mitigates the congestion in a feasible amount of time. It is implemented on top of NCCL, so users can transparently use TCCL without any code modification. It outperforms existing libraries NCCL and MSCCL by up to \(2.07\times\). It can efficiently accelerate diverse GPU applications, including DL training proven to have \(1.09\times\) average speedup after using TCCL with different parallelism strategies.
Additional notes
Finally, I want to discuss two future research topics that stem from TCCL:
- Finding the root cause of CPU congestion
- Inter-node pathfinding when nodes have multiple NICs
I want to note that Topic #1 is a known, but not resolved problem yet, as far as I know. We were fortunate to talk with Prof. John Kim (KAIST) at ASPLOS 2024 and he shared that similar problems were observed in his paper. Topic #2 is also an important problem, as modern systems are usually equipped with multiple NICs but it is difficult to efficiently leverage them, as far as I know is true with MPI. Finally, I want to thank Mert Hidayetoglu (Stanford) for his feedbacks during ASPLOS poster session (Checkout his recent work HiCCL on collective communication library! – added Aug. 31, 2024).